Understanding Document Chunks
When you upload a document to your knowledge base, the system automatically divides it into smaller segments called “chunks.” This chunking process is crucial for:- Improved LLM Processing: Allows large language models to process manageable portions of text.
- Enhanced Retrieval: Enables more precise information retrieval by pinpointing relevant sections.
- Optimized Performance: Reduces computational load and improves response times.
Accessing Document Chunks
 You’ll see a list of
chunks derived from the original document.
You’ll see a list of
chunks derived from the original document.Enhancing Document Chunks
Improve the quality of your chunks for better matching by enriching their metadata: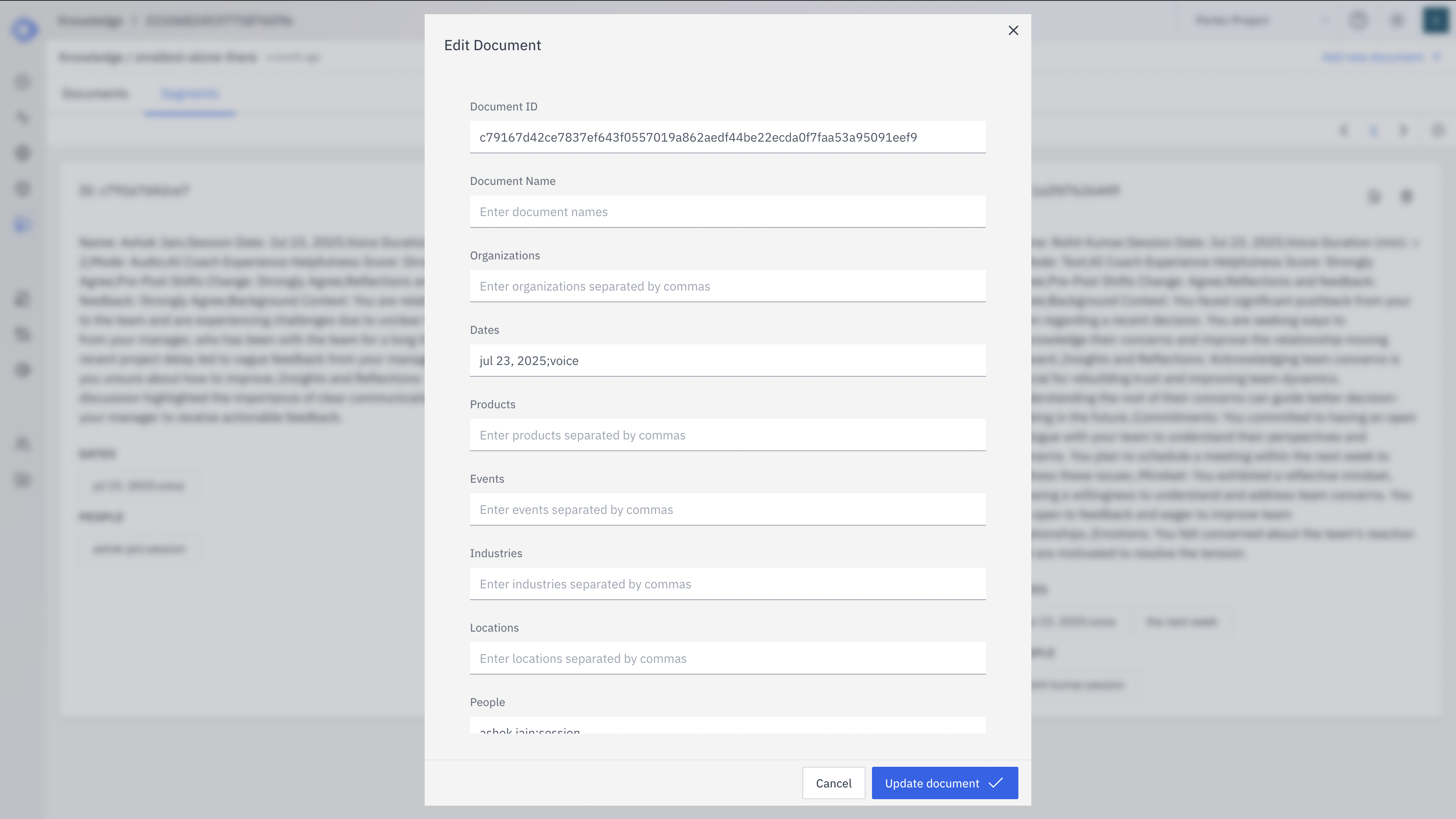
Metadata Fields
Document Name
Document Name
The title or identifier for this chunk
Organizations
Organizations
Relevant company or group names
Dates
Dates
Important dates mentioned in the content
Products
Products
Product names or types discussed
Events
Events
Significant events referenced
Industries
Industries
Related industry sectors
Locations
Locations
Geographic locations mentioned
People
People
Names of individuals relevant to the content
Search Types
When querying your knowledge base, you can utilize different search methods:Hybrid Search
Combines semantic understanding with keyword matching. Ideal for balancing
context-aware results with exact matches.
Full Text Search
Focuses on exact keyword matches within the text. Best for finding specific
terms or phrases.
Semantic Search
Emphasizes understanding the meaning and context of the query. Excellent for
natural language queries and user intent.