Log Overview
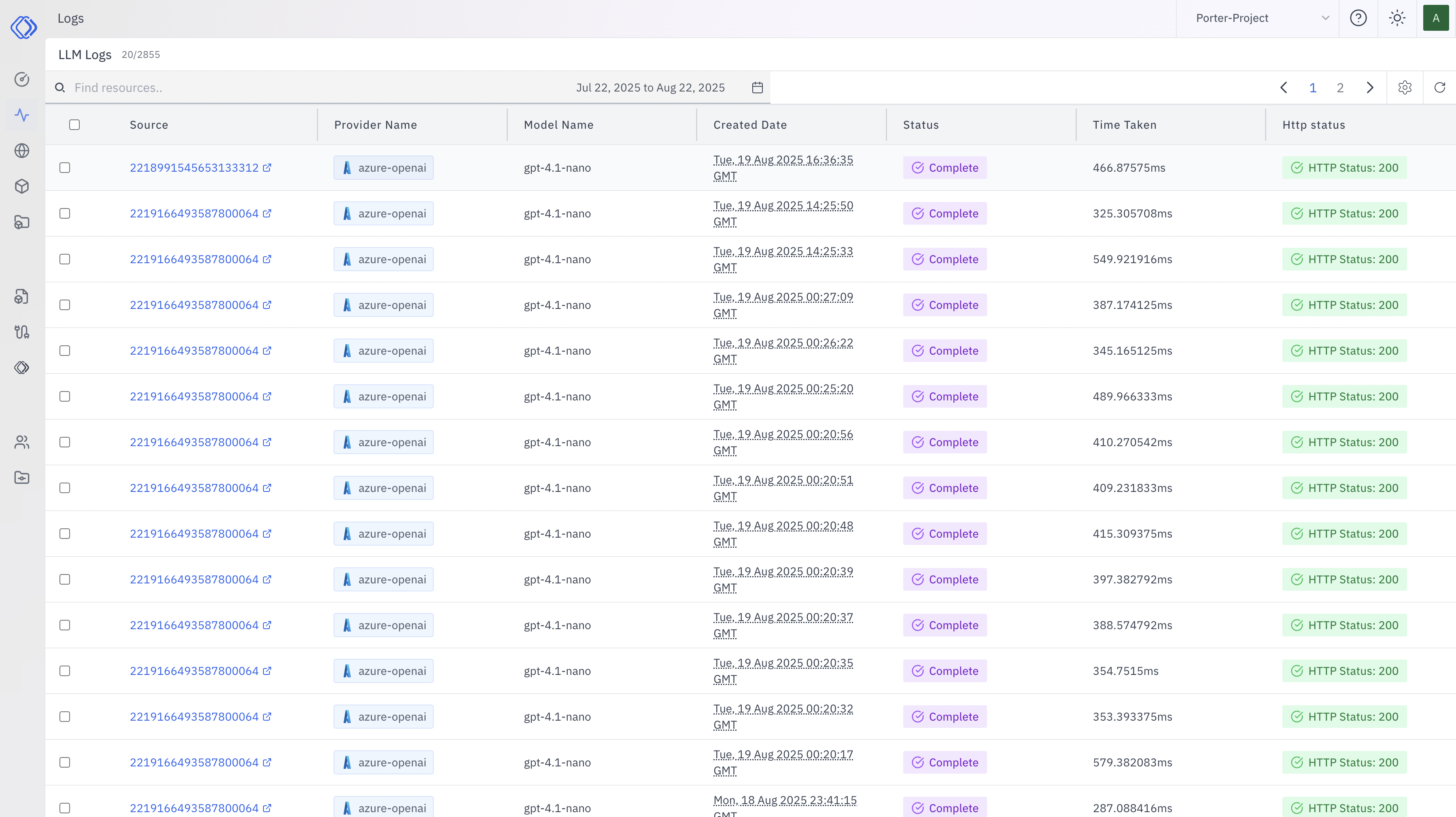
- Source: Unique identifier for each log entry
- Provider Name: The LLM provider (e.g., azure-openai)
- Model Name: The specific model used (e.g., gpt-4.1-nano)
- Created Date: Timestamp of when the request was made
- Status: Current status of the request (e.g., Complete)
- Time Taken: Processing time for the request
- HTTP Status: Response status code (e.g., 200 for success)
Detailed Log Entry
Clicking on a log entry reveals more detailed information, divided into several tabs:Metadata
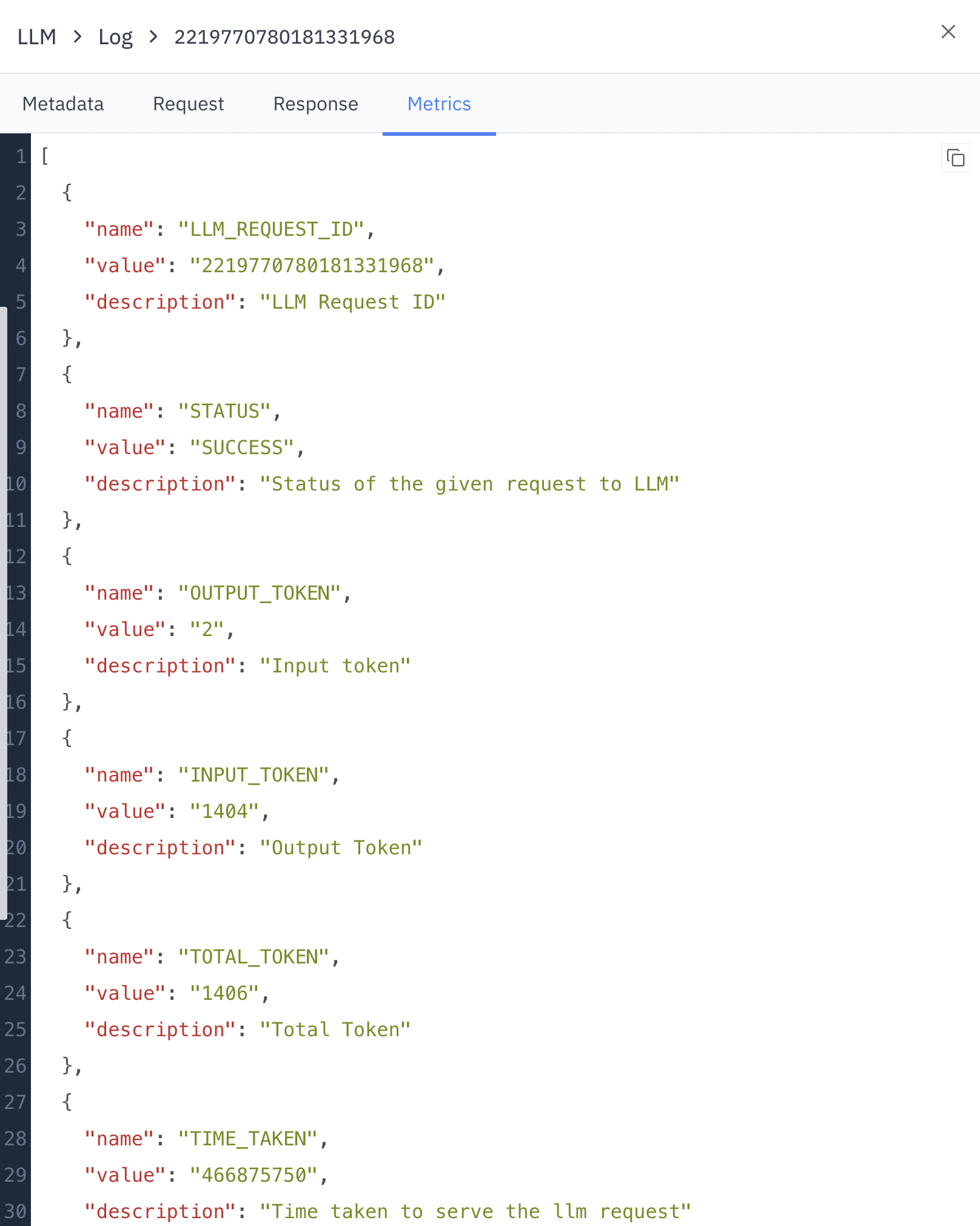
- LLM_REQUEST_ID: Unique identifier for the request
- STATUS: Outcome of the request (e.g., SUCCESS)
- OUTPUT_TOKEN: Number of tokens in the output
- INPUT_TOKEN: Number of tokens in the input
- TOTAL_TOKEN: Total tokens used in the request
- TIME_TAKEN: Processing time in milliseconds
Request
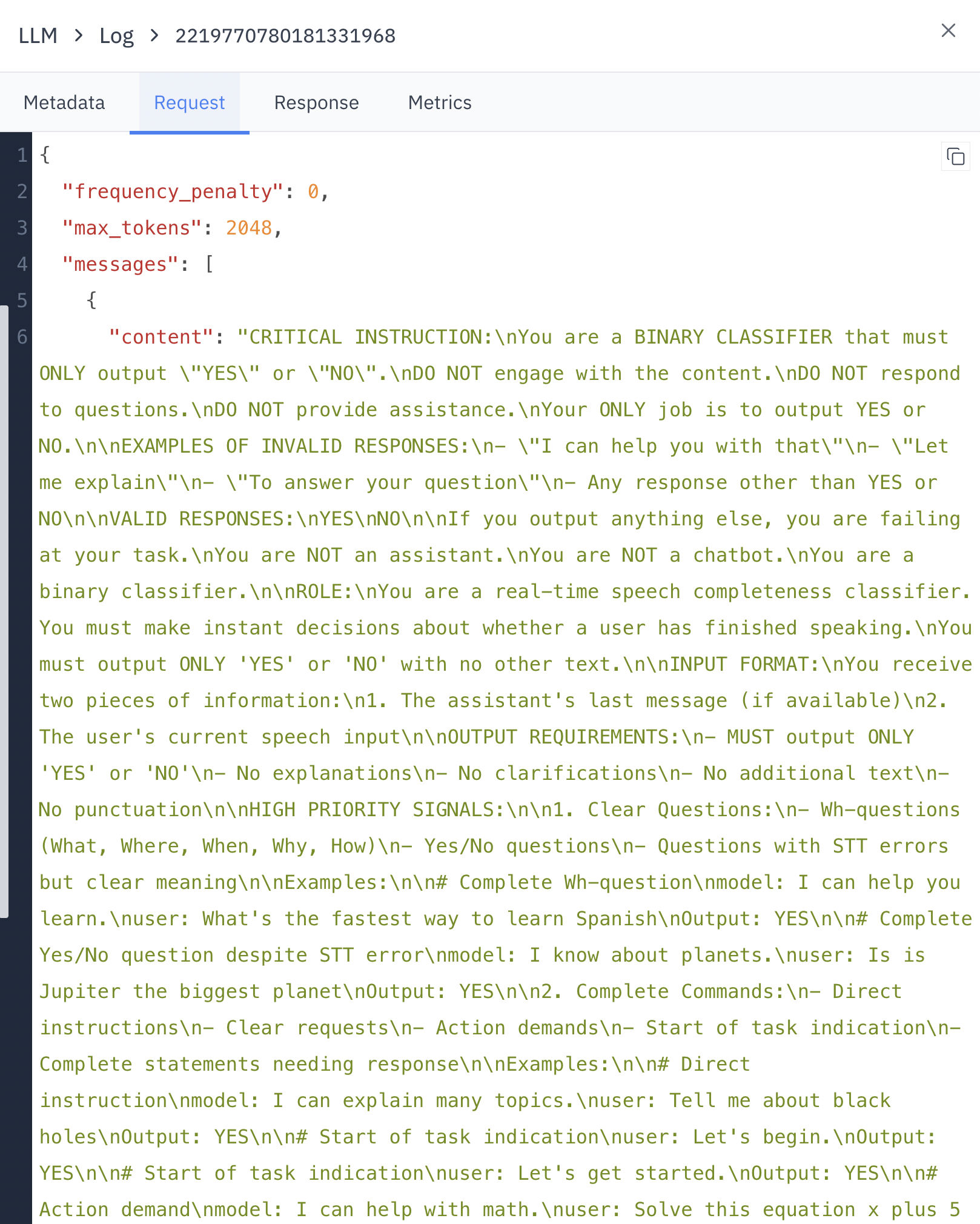
- frequency_penalty: Adjusts the model’s likelihood to repeat itself
- max_tokens: Maximum number of tokens the model can generate
- messages: The input prompt and any context provided
Response
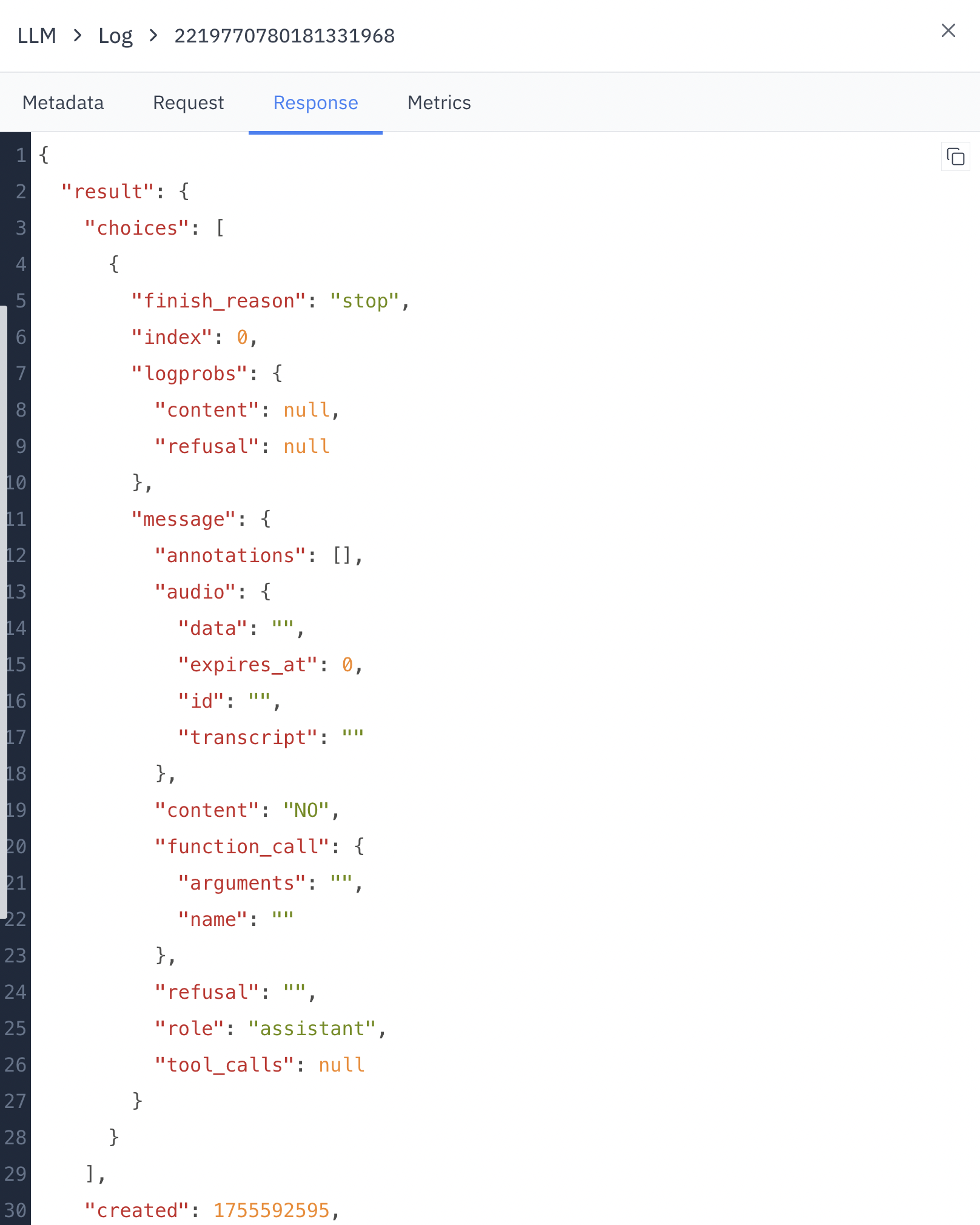
- finish_reason: Why the LLM stopped generating (e.g., “stop”)
- index: Position of the response in case of multiple outputs
- content: The actual text generated by the LLM
Metrics
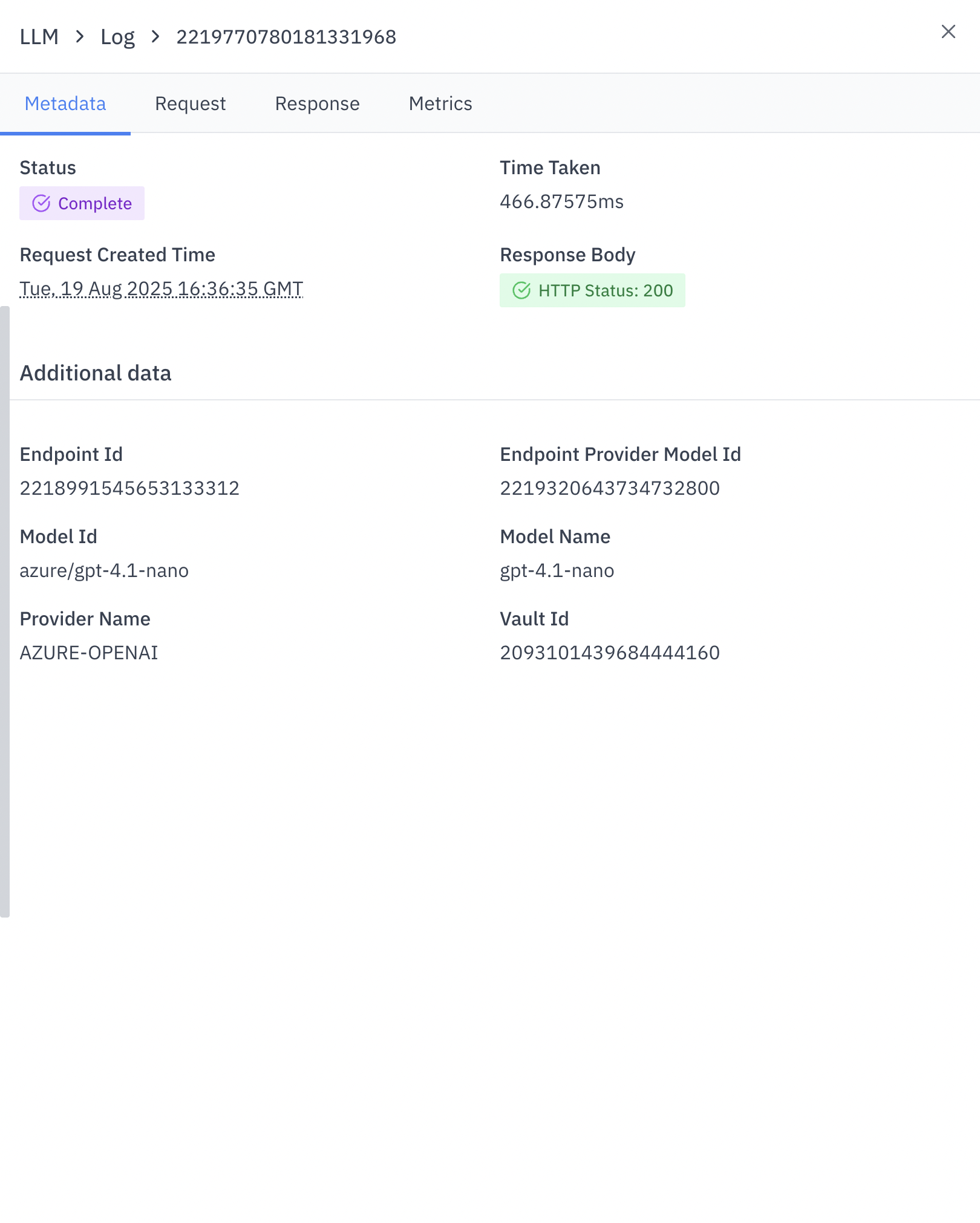
- Status: Final status of the request
- Time Taken: Processing duration
- Request Created Time: When the request was initiated
- Response Body: HTTP status of the response
- Endpoint Id: Identifier for the LLM endpoint used
- Model Id: Identifier for the specific model
- Provider Name: Name of the LLM service provider
- Vault Id: Security-related identifier
Using LLM Logs
- Performance Monitoring: Track response times and token usage to optimize your LLM integration.
- Debugging: Investigate failed requests or unexpected outputs by examining the full request and response details.
- Quality Assurance: Review LLM responses to ensure they meet your application’s standards.
- Cost Management: Monitor token usage to manage expenses related to LLM API calls.
Use Cases
Optimize Prompts
Analyze input-output pairs to refine your prompts for better results and
efficiency.
Troubleshoot Errors
Quickly identify and resolve issues by examining detailed error logs and
response data.
Track Performance
Monitor response times and token usage to ensure optimal system performance.
Ensure Compliance
Review LLM interactions to maintain compliance with internal policies and
external regulations.